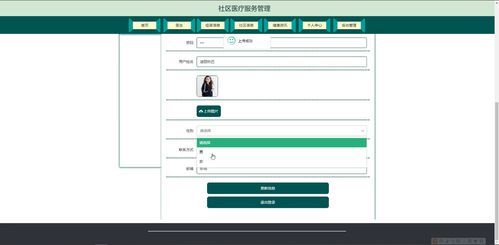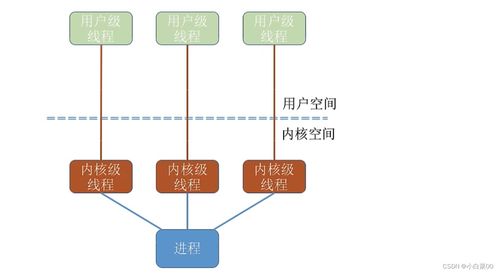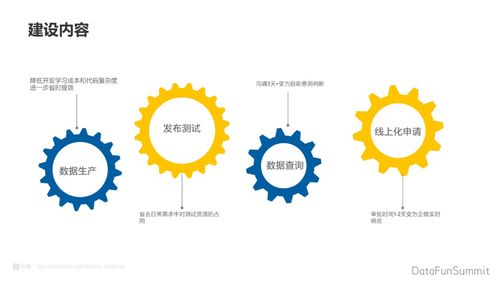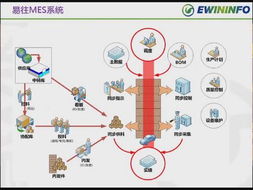
計算機視覺作為人工智能領(lǐng)域的重要分支,其知識體系構(gòu)建離不開高效的數(shù)據(jù)處理流程。數(shù)據(jù)處理不僅是計算機視覺應用的基礎,更是模型性能提升的關(guān)鍵環(huán)節(jié)。
數(shù)據(jù)采集是計算機視覺的起點。高質(zhì)量的數(shù)據(jù)來源包括開源數(shù)據(jù)集、網(wǎng)絡爬取、傳感器采集等多種方式。以圖像識別為例,數(shù)據(jù)采集需覆蓋不同光照、角度、背景等變量,確保數(shù)據(jù)的多樣性和代表性。
數(shù)據(jù)預處理環(huán)節(jié)包括圖像清洗、格式統(tǒng)一和尺寸標準化。通過去除噪聲圖像、糾正扭曲、調(diào)整亮度和對比度等操作,可以顯著提升后續(xù)分析的準確性。例如在目標檢測任務中,標準化圖像尺寸能夠保證卷積神經(jīng)網(wǎng)絡的輸入一致性。
數(shù)據(jù)增強技術(shù)是提升模型泛化能力的重要手段。通過旋轉(zhuǎn)、縮放、裁剪、色彩變換等方法對原始數(shù)據(jù)進行擴充,可以有效防止過擬合。在深度學習模型中,適當?shù)臄?shù)據(jù)增強可以使模型在有限的數(shù)據(jù)集上獲得更好的表現(xiàn)。
特征工程是數(shù)據(jù)處理的核心環(huán)節(jié)。在計算機視覺領(lǐng)域,這包括傳統(tǒng)特征提取方法(如SIFT、HOG)和基于深度學習的特征表示。現(xiàn)代計算機視覺系統(tǒng)通常采用端到端的深度學習模型,自動學習圖像的特征表示。
數(shù)據(jù)標注的質(zhì)量直接影響監(jiān)督學習的效果。在目標檢測、語義分割等任務中,需要精確的邊界框標注和像素級標注。隨著主動學習技術(shù)的發(fā)展,智能標注系統(tǒng)能夠顯著提升標注效率。
數(shù)據(jù)管理包括數(shù)據(jù)存儲、版本控制和隱私保護。在大規(guī)模計算機視覺應用中,需要建立完善的數(shù)據(jù)流水線,確保數(shù)據(jù)的可追溯性和安全性。特別是在醫(yī)療影像、自動駕駛等敏感領(lǐng)域,數(shù)據(jù)隱私保護尤為重要。
數(shù)據(jù)處理貫穿計算機視覺應用的整個生命周期。從數(shù)據(jù)采集到最終部署,每一個環(huán)節(jié)都需要精心設計和優(yōu)化。隨著人工智能技術(shù)的不斷發(fā)展,數(shù)據(jù)處理方法也在持續(xù)演進,為計算機視覺的進步提供堅實的數(shù)據(jù)基礎。